Fonemų atpažinimas
Fonemos sąvoka
Kalbant apie fonemų atpažinimą pirma reikėtų išsiaiškinti fonemos termino prasmę. Mes nuo mokyklos laikų žinome raidžių (a, ą, b, c, ... ,ž) prasmę. Raidės naudojamos rašytine forma užrašyti kalbą, mintis ir panašiai. Fizine prasme kalba susidaro kalbos padagrais (http://ualgiman.dtiltas.lt) generuojant atmosferinio slėgio mikropokyčius, kurie plinta oru ir yra priimami bei suvokiami žmogaus klausos aparatu.
Fonema yra vadinama neskaidoma elementari kalbą sudarančio garsinio signalo dalis. Panašiai kaip ir raidžių atvejų, kiekviena kalba turi jai būdingų fonemų (garsų) baigtinį sąrašą, kurį galima vadinti "fonemų abėcėle". Lietuvių kalbai fonemų abėcėlė kol kas nėra standartizuota, tačiau kuriant kalbos sintezavimo sistemas autoriai sudaro tokių fonemų sąrašus. Plačiau apie tai galite paskaityti P. Kasparaitis. Kompiuterinė lingvistika.
Fonemų skaitmeniniai signalai
Kalbos signalą sudarantys atmosferinio slėgio mikropokyčiai vadinami
garso slėgiu. Matematine prasme garso slėgis yra reali
vieno tolydaus kintamojo (laiko t) funkcija.
Inžinerijoje tokio tipo funkcijos vadinamos analoginiais signalais.
Tačiau kompiuteriais apdoroti tiesiogiai analoginių signalų negalima,
nes jie pritaikyti apdoroti skaitmeninę informaciją
(t.y. informaciją, kuri išreiškiama baigtine 0/1 seka).
Todėl specialūs įrenginiai (pvz. asmeninių kompiuterių garso plokštės)
diskretizuoja analoginį signalą laike ir kvantuoja
garso slėgio reikšmes.
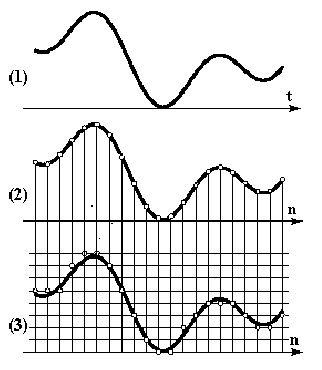
1 paveikslėlis iliustruoja analoginio signalo diskretizavimo ir kvantavimo operacijas, kurias atlikus, analogonis signalas (1) po diskretizavimo laike virsta diskretiniu signalu (2), o po reikšmių kvantavimo - skaitmeniniu signalu. Dabartiniuose kompiuteriuose saugomi tik skaitmeniniai signalai.
1 paveikslėlis. Analoginio signalo (1)
diskretizavimas laike (2) ir reikšmių kvantizavimas (3)
http://www.mif.vu.lt/~pijus/CL/KircTr.pdf
Fonemų atpažinimo kompiuteriu uždavinys
Rašytinio teksto užrašymas fonemomis (garsais) vadinamas transkripcija. Sprendžiant kalbos atpažinimo uždavinį kompiuteriu galima imituoti skaitymo procesą. Mokykloje mes pirma išmokome atpažinti rašytinio teksto atskiras raides ("a", "b" ir t.t.), po to jas jungėme į skiemenis ir t.t. Pirmojo skaitymo išmokimo etapo ("raidžių atpažinimas") analogas kalbos kompiuterinio atpažinimo atveju būtų "fonemų atpažinimas". Šiuo atveju vietoje analoginių grafinių simbolių turime kalbos signalo skaitmenį signalą kompiuteryje, kurį reikia paversti vienu kokios nors fonemos simboliu.
2 ir 3 paveikslėliuose pateikti trumpojo balsio "a" ir sprogstamojo priebalsio "b" skaitmeninių įrašų pavyzdžiai. Atkreikite dėmesį, skiriant garsus nuo raidžių, garsų atveju susitarta naudoti balsis ar priebalsis terminus, o raidžių atveju sakoma balsė ar priebalsė.
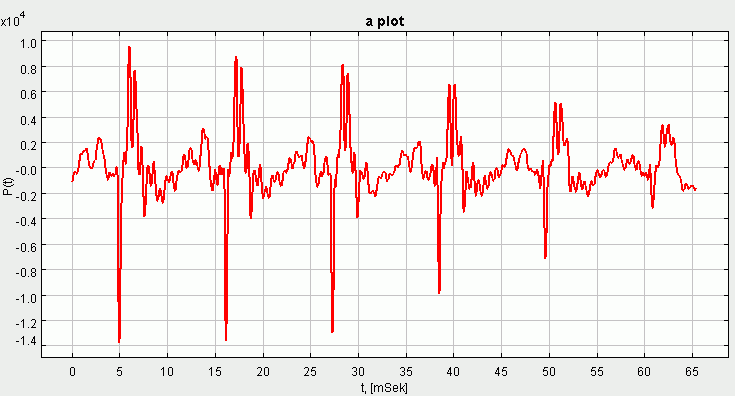
2 paveikslėlis. Balsio "a" skaitmeninio įrašo pavyzdys
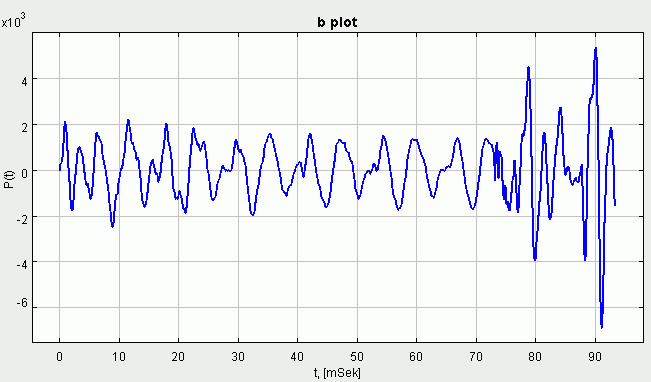
3 paveikslėlis. Priebalsio "b" skaitmeninio įrašo pavyzdys
Šnekamosios kalbos kompiuterinio atpažinimo uždavinys yra labai sudėtingas. Šio uždavinio sudėtingumą lemia tokie faktoriai:
Tarp fonemos skaitmeninį signalą lemiančių faktorių mes nepaminėjome kalbos stiprumo (garsio) parametro. Jei diktorius kalba pastoviu garsiu, šis faktorius nėra esminis, kadangi nesunku normuoti garsį padauginant skaitmeninį fonemos signalą iš konstantos.
Šiame kurse nespręsime bendro šnekamosios kalbos atpažinimo kompiuteriu uždavinio, o tik susipažinsime kokiais būdais galima bandyti nustatyti kokią fonemą atitinka iškirtas atskiro garso skaitmeninis įrašas.
Lango funkcijos
Fonemų skaitmeninius signalus
stengiamasi glaustai aprašyti nedideliu kiekiu skaitinių parametrų,
kurie apskaičiuojami iš signalo. Gauti parametrai vadinami
požymiais, kurie ir yra pateikiami atpažinimui.
Prieš pereidami prie fonemų skaitmeninių signalų konkrečių
požymių aprašymo, susipažinsime su klasikiniu pirminiu signalo
apdorojimu, vadinamu dauginimu iš lango funkcijos.
Šio veiksmo esmė labai paprasta - kiekviena skaitmeninio signalo
reikšmė yra dauginama iš fiksuotos lango funkcijos daugiklio ("svorio"),
kurio reikšmė priklauso nuo taško indekso. Lango funkcija parenkama
taip, kad svoriai būtų maži neneigiami skaičiai arti signalo
kraštų ir arti vieneto indekso reikšmėms, kurios yra arti signalo
centro. Tokiu būdu yra sprendžiama taip vadinama "krašto" problema,
nes fonemos skaitmeninis signalas "išpjaunamas" iš kalbos signalo
ir todėl kraštinės reikšmės yra nelabai natūralios fizikine prasme.
Pavyzdžiui mažiausią indeksą atitinkanti reikšmė gali būti didelė,
nors natūralūs signalai kaip taisyklė prasideda nuo artimomis nuliui
reikšmėmis. Taip pat dažnai fonemų kraštinės reikšmės yra įtakojamos
gretimų fonemų reikšmėmis, dėl ko padidėja tikimybė fonemą atpažinti neteisingai.
Tarkime skaitmeninės fonemos reikšmės yra
x0, x1, x2, ... , xN-1,
o lango "svorius" (angl. weights) žymėsime
w0, w1, w2, ... , wN-1. Tuomet trikampis, Haningo ir Hamingo langai bus apibrėžti tokiomis formulėmis:
wn = min(n,N-1-n)/((N-1)/2)
wn = 0.5(1-cos(2p n/(N-1))
wn = 0.54-0.46cos(2p n/(N-1))
4 paveikslėlis iliustruoja skaitmeninės fonemos "a" apdorojimą Hamingo langu. Hamingo langas dažniau taikomas trumpiems signalams (iki 0.1 sek), o Haningo - ilgesnės trukmės signalams.
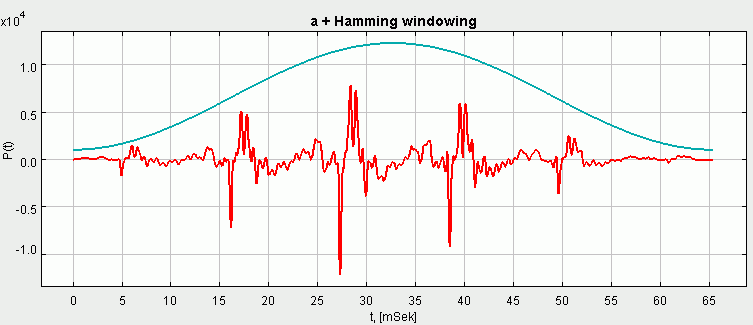
4 paveikslėlis. Balsis "a" apdorotas Hamingo langu
Paprasčiausi fonemos požymiai
Fonemoms atpažinti naudosime klasikinę schemą, t.y.
P = 1/(N*FS) S0 ≤ n < N (sn)2
E = 1/FS S0 ≤ n < N (sn)2
M = 1/N S0 ≤ n < N | sn |
A+ = max0 ≤ n < N sn
A- = min0 ≤ n < N sn
A = A+ - A-
#Z = FS/N { #n: 0 < n < N, sgn(sn-1) != sgn(sn) }
Čia FS žymi imčių dažnį
(kompaktinių diskelių įrašymui dažniausiai naudojama FS=44100),
o sn "pasvertos" fonemos skaitmeninės reikšmės, t.y
sn = wnxn .
Pailiustruosime kaip priklauso paprasčiausi fonemų parametrai nuo
tų pačių fonemų skirtingų egzempliorių. Visose pateiktose iliustracijose
raudonas taškas vaizduos 2 paveikslėlyje pateiktos "a" fonemos,
parametrus.
Morkavi taškai žymi kitų "a" fonemos egzempliorių parametrus.
Viso analizuojami 144 skirtingi trumpojo "a" balsio variantai.
Žalsvai pilki taškai žymi kitų "b" fonemos egzempliorių parametrus.
Viso analizuojami 86 skirtingi trumpojo "b" priebalsio variantai.
Priminsiu, kad visais atvejais, prieš skaičiuojant fonemos parametrus, jai buvo pritaikytas Hemingo langas (žiūr. 4 pav.). Vizualiai parametras laikytinas sėkmingu, jei morkavi ir raudonas taškai grupuojasi vienoje srityje, o mėlyni ir pilki - kitoje skirtingoje srityje.
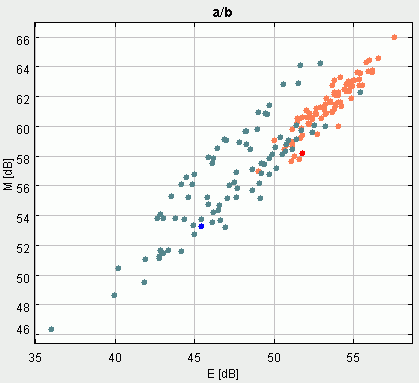
5 paveikslėlis iliustruoja "a" ir "b" fonemų skirtingų egzempliorių galingumo (N) ir energijos (E) parametrų reikšmes. 6 paveikslėlyje abscisių atidėtos fonemų modulio vidurkio (M) reikšmės, o ordinačių - energijos E reikšmės. Visais atvejai parametrai išreiškiami decibelais, t.y. apskaičiuojama gauto parametro dešimtainis logaritmas ir dauginama iš 10 (N ir E atveju) arba iš 20 (M atveju). Decibelais patogu matuoti teigiamus plačiame diapazone kintančius dydžius (energiją aprašantys parametrai N, E ir M tokia savybe pasižymi). Kaip ir galima buvo tikėtis visų trijų parametrų reikšmės gana ryškiai koreliuoja. Pavyzdžiui, jei kokiu nors atveju fonemos vidutinis galingumas N santykinai didelis, tai tikėtina, kad fonemos energija bus santykinai taip pat didelė. Iš pirmo žvilgsnio gali būti kiek netikėta, kad fonemos energiją aprašantys parametrai gana neblogai skiria "a" ir "b" fonemų grupes. Tai galima paaiškinti tuo, kad sprogstamasis priebalsis "b" didelia dalimi tariamas esant suglaustom lūpoms. "a" tariamas visuomet atvertomis lūpomis, todėl plaučiuose sukauptas viršslėgis laisvai patenka į kalbos traktą ir dėl to gauname didesnės energijos (lyginant su "b" atveju) garso signalą.
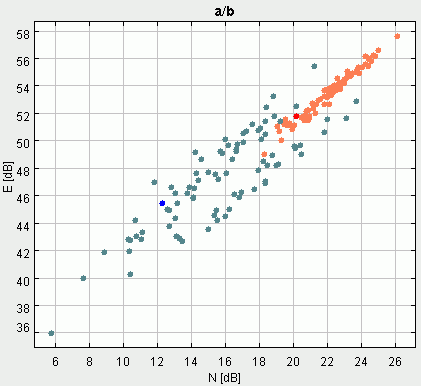 |  |
5 paveikslėlis (kairiau). "a" ir "b" fonemų skirtingų egzempliorių energijos ir galingumo parametrai
6 paveikslėlis (dešiniau). "a" ir "b" fonemų skirtingų egzempliorių modulio vidurkio ir energijos parametrai
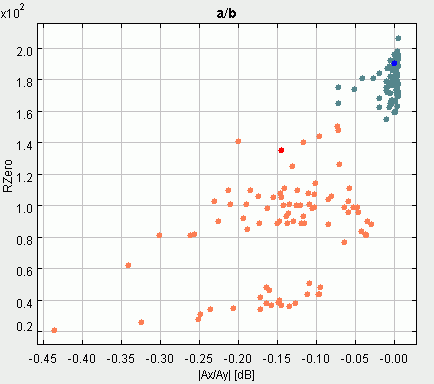
7 paveikslėlyje abscisių ir ordinačių ašyse atidėtos "a" ir "b" fonemų
maksimalios (Ap) ir minimalios (Am) amplitudės, o
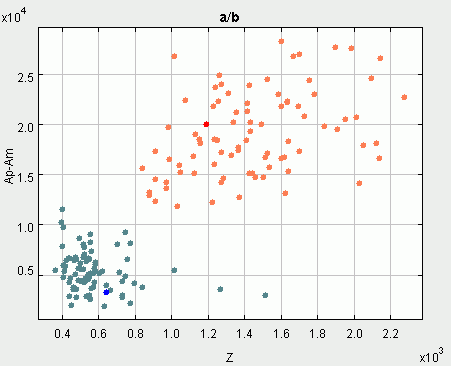
8 paveikslėlyje - nulio kirtimų vidutinio dažnio (Z)
ir amplitudės (A = Ap-Am) parametrų reikšmės. Kaip matyti iš paveikslėlių,
ir viena ir kita parametrų pora puikiai skiria visus "a" ir "b" egzempliorus.
Toks rezultatas netiesiogiai byloja, kad šių fonemų akustinės savybės gana
ryškiai skiriasi. Kaip ir galima buvo tikėtis, dėl analogiškų samprotavimų
apie pravertas ir suglaustas lūpas, "a" tipo fonemų maksimalios ir minimalios amplitudės
moduliu yra didesnės nei "b" tipo fonemų. "b" fonemos egzempliorių vidutinis
nulių kirtimų dažnis kinta nuo 300 iki 1000 (su retomis išimtimis),
o "a" atveju - nuo 1000 iki 3000 hercų. Šie skaičiai atspindi vizualiai
lengvai pastebimą 2 ir 3 paveikslėliuose faktą, kad "a" balsyje vyrauja
aukštesnio dažnio kompenentės, lyginant su "b" atveju.
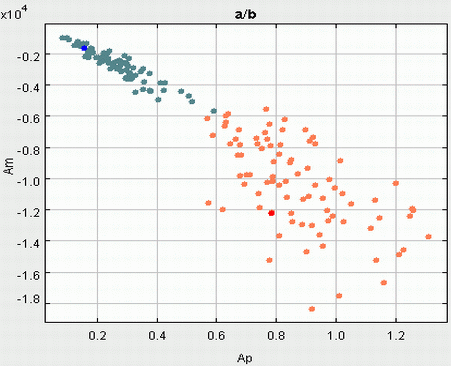 |  |
7 paveikslėlis (kairiau). "a" ir "b" fonemų maksimalios (Ap) ir minimalios (Am) amplitudės
8 paveikslėlis (dešiniau). "a" ir "b" fonemų nulio kirtimų vidutinio dažnio (Z)
ir amplitudės (A = Ap-Am) parametrų reikšmės
Adaptyvūs požymiai
Pereitame skyrelyje susipažinote su tiesinės prognozės požymiais. Šie požymiai arba išvestiniai iš jų dažnai ir sėkmingai naudojami kalbos atpažinime. Tačiau jie nesprendžia visų problemų. Vienas trūkumų - tiesinės prognozės (LPC) koeficientai nėra adaptyvūs, t.y. pvz. skiriant "a" ir "b", "b" ir "c", "c" ir "a" tipo fonemų poras bus naudojami vieni ir tie patys LPC požymiai. Todėl kyla mintis modifikuoti LPC metodą taip, kad jis adaptyviai skirtų poras, pvz. "a" ir "b" porai parinktų vienus parametrus, o "b" ir "c" porai - kitus. Šią idėją galima praplėsti ir toliau parenkant adaptyvius parametrus kiekvienai "a" ir "b" tipo fonemų egzempliorių porai.
Signalo
x0, x1, x2, ... , xN-1
LPC koeficientų reikšmes lemia tiesinės prognozės
xn = (-Sk=1)P akxn-k) en
išraiška. Kaip matyti šioje išraiškoje dalyvauja tik vienos fonemos "x" duomenys, todėl ir nėra LPC koeficientų adaptyvumo (prisitaikymo) prie norimų atskirto fonemų porų.
Tarkime turime signalų poros "x" ir "y" garso slėgio duomenis:
x0, x1, x2, ... , xN-1;
y0, y1, y2, ... , yM-1;
Užrašykime nuo dviejų parametrų a ir b priklausančią išraišką:
Ix,y(a,b) = (Sn=1N-2 (axn-1 + xn + bxn+1)2) / (Sn=1M-2 (ayn-1 + yn + byn+1)2)
Susitarkime Ix,y(a,b) minimizuoti atžvilgiu laisvų parametrų a ir b. Norint, kad iš axn-1 + xn + bxn+1 ir ayn-1 + yn + byn+1 būtų galima stabiliai rekonstruoti xn ir yn reikšmes, pareikalaukime papildomos sąlygos:
|a| + |b| ≤ 1 .
Nesunku apskaičiuoti, kad
Ix,y(a,b) =
( (1+a2+b2) Rxx[0] +
2 (a+b) Rxx[1] +
2 ab Rxx[2] ) /
( (1+a2+b2) Ryy[0] +
2 (a+b) Ryy[1] +
2 ab Ryy[2] )
Čia Rxx ir Ryy žymi atitinkamai x ir y signalų autokoreliacinę funkciją. Gautą sąlyginio minimizavimo uždavinį galima spręsti apskaičiuojant Ix,y(a,b) dalines išvestines a ir b parametrų atžvilgiu ir prilyginant jas nuliui. Tačiau daugeliu atveju taip gautos a ir b reikšmės netenkins stabilumo sąlygos, todėl galima tiesiog kompiuteriu sudaryti Ix,y(a,b) reikšmių lentelę (imant a ir b reikšmes tenkinančias stabilumo sąlygą) ir išsirinkti mažiausią. Tokiu būdu rasite apytikslį sąlyginio minimizavimo uždavinio sprendinį.
Kokia gautų a ir b parametrų prasmė. Iš Ix,y(a,b) išraiškos matyti, kad a ir b vienu metu linkę xn aproksimacijos axn-1 + xn + bxn+1 paklaidą ( xn -(axn-1 + bxn+1) )2 minimizuoti, o yn aproksimacijos ayn-1 + yn + byn+1 paklaidą - maksimizuoti. Tokiu būdu pasiekiamas gaunamų parametrų adaptyvumas prie pasirinktos poros (šiuo atveju "x"/"y" poros).
Aprašytą procesą galima tęsti xn ir yn duomenis pakeičiant aproksimacijos paklaidomis:
xn -(axn-1 + bxn+1) ) ir
yn -(ayn-1 + byn+1) )
Atlikę tokių P žingsnių gautume P a ir b koeficientų porų, kurie kartu sudarytų xn ir yn tiesinio aproksimavimo operatorius. Skirtingai nuo klasikinės tiesinės prognozės schemos - xn ( analogiškai yn ) tiesinė prognozė atliekama iš abiejų pusių.
Atkreipkime dėmesį į vieną Ix,y(a,b) minimizavimo trūkumą. "x"/"y" poroje abi fonemos "x" ir "y" įeina simetriškai, tačiau minimizuojant atsiranda asimetrija, kadang skaitiklis, aprašomas "x" duomenimis yra minimizuojamas, o vardiklis, aprašomas "y" duomenimis yra maksimizuojamas. Galimi du šios problemos sprendimo būdai: arba atlikti atskirai Ix,y(a,b) maksimizavimą, arbą atskirai minimizuoti Iy,x(a,b) išraišką. Anttrasis būdas programavimo prasme priimtinesnis, nes pakaks realizuoti vieną minimizavimo procedūrą ir kreiptis į ją su (x,y) ir (y,x) parametrų poromis.
 | 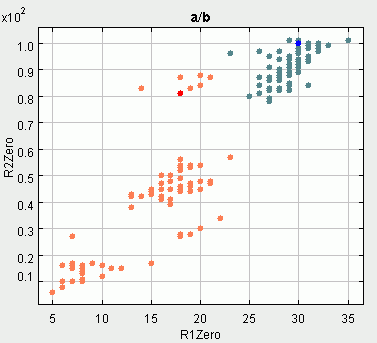 |
9 paveikslėlis (kairiau). "a" ir "b" fonemų autokoreliacijos pirmasis ir antrasis nuliai
10 paveikslėlis (dešiniau). "a" ir "b" fonemų adaptyvioji charakteristika ir autokoreliacijos 3pirmasis + antras nuliai
Kepstro požymiai
"Kepstro" terminas kilęs iš dalinai apgręžto "spektro" žodžio. Plačiau apie šį žodžių žaismą ir kaip apskaičiuojami garso kepstriniai požymiai aprašyta čia.
Praktinis darbas
Realizuokite fonemų atpažinimo algoritmą Java kalba.
Jūsų atpažinimo algoritmas bus vertinamas pagal
pateiktų algoritmui nežinomų fonemų atpažinimo kokybę.
Reikalingą algoritmui fonemų sąrašą ir duomenis rasite čia. Failuose su .raw galūne įrašytos vienos fonemos egzempliorių klasteris. Informacija apie klasterio atskiros fonemos ilgį pateikta to paties vardo .dat galūnės faile. Šiame faile surašytos iš eilės einančių fonemų fonogramų ilgiai (imčių kiekis). Failo pavadinimas yra vienos fonemos vardas. Šis fonemų sąrašas paimtas iš Pijaus Kasparaičio lietuvių kalbos sintezavimo sistemos. Čia mes laikome, kad skirtingai kirčiuotos fonemos skiriasi. Šiame sąraše yra 91 skirtinga fonema.
.raw faile surašytos iš eilės einančios imtys. Imčių diskretizavimo dažnis FS=22050. Vienai imčiai skirti du baitai, pirma eina vyresnysis baitas.
Kuriant atpažinimo algoritmą jums reikės apskaičiuoti tiesinės prognozės koeficientus. Jų skaičiavimui galite panaudoti LPC.zip, 22 k Java LPC klasę ir jos kodą.
Derinant atpažinimo algoritmą susidursite su testinių duomenų problema. Tuo tikslu galite pasinaudoti tokia tradicine metodika. Išsirinkite iš pateikto fonemų duomenų banko pirmosios fonemos pirmąjį egzempliorių X ir išmeskite šį egzempliorių iš fonemų duomenų banko, bei pritaikykite fonemai X savo atpažinimo algoritmą. Kartokite šią procedūrą vietoje X imdami pirmosios fonemos antrąjį, trečiąjį ir t.t. egzempliorius. Po to kartokite tą pačią procedūrą su antrąja, trečiąja, ..., 91-ąja fonema. Tokiu būdu jūs sukaupsite statistiką apie "nežinomų" fonemų atpažinimo kokybę (procentą teisingai atpažintų fonemų) ir galėsite parinkti laisvus algoritmo parametrus maksimizuodami teisingai atpažįstamų fonemų procentą.
Reikalavimas programai:
Jūsų klasė turi praplėsti (extends) fonemos paketo Fonemos klasę.
fonemos paketo klasių kodas yra čia.
Literatūra