Inputs arrive from other neurons, or
from the environment. By taking the inner product, the neuron
essentially multiplies each input it receives by a weight which is
specific to that input. (This is loosely based on the fact that
real neurons are connected by synapses that vary in strength. Any
given neuron in the brain receives inputs from as many as thousands of
other neurons, and it pays more "attention" to some than to others.) The
neuron adds all of these weighted activations together, along with any
bias that it might have, to form the inner product. The inner
product is then subjected to a transfer function which is preferably
nonlinear. The result is the neuron's output.
Backpropagation networks consist of
either two or three layers of neurons, and all the neurons behave as shown
above. Any given neuron receives input from all neurons in the preceding
layer, and it sends its output to all neurons in the layer below. In the
case of the input layer, the inputs are what we put into the network, and
in the case of the output layer, the outputs are what we get from it.
Introduction One of the
most typical problems to which a neural network is applied is that of
optical character recognition. Recognizing characters is a problem that at
first seems extremely simple- but it's extremely difficult in practice to
program a computer to do it. And yet, automated character recognition is
of vital importance in many industries such as banking and shipping. The
U.S. post office uses an automatic scanning system to recognize the digits
in ZIP codes. You may have used scanning software that can take an image
of a printed page and generate an ASCII document from it. These devices
work by simulating a type of neural network known as a backpropagation
network.
Backpropagation neural
networks The algorithm behind
backpropagation networks was discovered independently by several research
groups at about the same time in 1985-86. The "neurons" in these networks
are inspired by biological neurons, which are much more complex in
comparison. The generic connectionist neuron commonly used in most types
of neural networks is extremely simple. A
backpropagation network usually consists of three (or sometimes fewer)
layers of neurons: the input layer, the hidden layer, and the output
layer. In the applet below, the input layer consists of eight neurons, and
the hidden layer contains 12. The size of the output layer is fixed by the
applet to ten neurons- because these are the neurons that are to fire
selectively according to which input is presented.
The backpropagation algorithm works by what
is known as supervised training. It first submits an input for a forward
pass through the network. The network output is compared to the desired
output, which is specified by a "supervisor" (the computer running the
simulation), and the error for all the neurons in the output layer is
calculated. The fundamental idea behind backpropagation is that the error
is propagated backward to earlier layers so that a gradient descent
algorithm can be applied. This assumes that the network can "run
backwards", meaning that for any two connected neurons, the "backward
weights" must be the same as the "forward weights". This isn't true for
real neurons, and so the backpropagation network is unbiological.
Yet, backpropagation is popular because it is well-known to generate
useful results when applied to real-world problems.
The OCHRE
applet This applet is named after what it does: Optical CHaracter
REcognition. Documentation is included below.
How to work
this thing
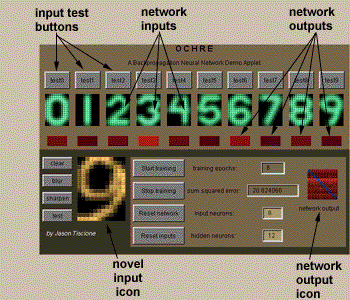
The ten
icons with the digits in them, along the the top of the applet window, are
the actual inputs that are used to test and train the neural network. To
submit one to the network, press the "test" button that appears above it.
The row of ten LEDs below the icons indicate the activity of the ten
output neurons. When the network is fully trained, the only active output
neuron should be the one below the icon which you just tested. It should
glow bright red, while the others remain black. But on startup, the
network is not trained yet- it doesn't "know" anything about what Arabic
numerals look like- and so it won't know how to recognize one. You're
likely to see all the neurons light up, at least a little bit.
To train the network, press the "Start
training" button on the lower panel. As the applet begins to train the
network, you will see the number of training epochs (individual
training iterations) increase, and the sum squared error (the
cumulative error in the network output) slowly decrease. You will also see
the network output icon changing (at the lower right side of the
applet). This icon summarizes all of the network's responses to all ten of
the training inputs. Squares in the icon that are blue indicate
appropriate responses by output neurons, and those that are red indicate
inappropriate responses. Training should take
a few minutes, and is complete after about 150-250 training epochs, when
the sum squared error reaches a low value (approximately 0.01). On my
Pentium-133, it usually takes about two minutes of training for the
network to reach an error that low. The network output icon should appear
as a diagonal row of bright blue squares. At this point, you can press the
"Stop training" button to stop training the network. If you press the
"test" buttons above each digit icon, the appropriate LED should now light
up. You can test the network on your own
hand-drawn symbol, by drawing one with your mouse in the large icon at the
lower left of the applet. Your left mouse button will light a pixel up,
and your right mouse button will darken it. (If your mouse only has one
button, you can click while holding down your ALT key to darken a pixel.)
You can blur or sharpen your drawing using the buttons along the left of
the large icon. To see what the network thinks you just drew a picture of,
press the "test" button at bottom, and see which of the LEDs light up. I
have varying luck with it. Sometimes the network recognizes my digit
immediately, and sometimes it refuses to unless the picture is smoothed
with the blur button. One interesting thing to do is to test the network
on a novel input, such as a letter "A". Neural networks behave
unpredictably with novel inputs. The network
can be trained on any of your own novel inputs as well. You should be able
to alter any of the digit icons at the top by drawing on it. To blur,
sharpen, or clear them, use your "B", "S", and "C" keys respectively. To
restore the original digits, press the "Reset inputs" button. To reset the
network itself, press the "Reset network" button. You can change the
number of input layer neurons and hidden layer neurons by changing the
numbers in the corresponding fields before pressing "Reset network". Too
few neurons, and the network will be unable to learn anything. Too
many, and overlearning becomes likely- the network learns the
specific training inputs so well that it won't tolerate any slight
deviation from them.
This is the applet layout. Feel free to
push buttons and draw on any of the icons! Use the "b" key to blur any
icon that you draw; in general the network does a better job of
recognizing "fuzzy" symbols.
Each input layer neuron "sees" all 192 elements of a network
input icon as a long array, strung out by rows. (This may seem unnatural,
but visual images are jumbled and rearranged in the retina and visual
cortex of mammals in what seems to be an even more confusing fashion- but
our vision is none the worse for it.) The input neuron pays more
"attention" to some of the icon's elements than to others. It broadcasts
its output to all the neurons in the hidden layer below it.
The source
code: The source code to the applet and the underlying neural network is
available below, as well as documentation (generated by javadoc). I tried
to keep the backpropagation algorithm as general as possible- all of the tasks
that are specifically related to optical character recognition are handled by
the applet itself. The applet and the AWT widgets are written in Java 1.0 for
browser compatibility (so don't be surprised if your JDK issues a compile-time
insult).
BackProp.java-
the neural network object. Documentation
for class BackProp Note that with the code as it is, you are limited
to a three layer network that uses a log-sigmoid transfer function (i.e.,
1/(1+e-x)) for all neurons. If you want to modify the code for your
own purposes, feel free to knock yourself out.
ochre.txt- file
containing definitions of the default symbol set. (Pressing a capital "P" over
an icon will dump its matrix definition to your Java console, if you want to
create your own default symbol set files.)
There are a number of other Internet
resources out there about programming neural networks in Java. I really
wrote this applet more to become familiar with the AWT and with
multithreading in Java than to create a new backpropagation class. But
when I couldn't find any (free) neural net Java classes that were suitable
for use in an applet like the one here, or that had their source code
available, I decided to write my own- which turned out to be pretty easy
anyway. It only took about a day. The applet itself took much longer.
Neural
Java-Neural Networks Tutorial with Java Applets obviously would fit into
this category. This is a site located in Lausanne, Switzerland, with
demonstration applets that show the concepts behind different kinds of neural
networks.
Web Applets for
Artificial Neural Learning - This site contains some simple
applets that demonstrate graphically how artificial neurons work and how some
elementary neural networks are put together.
Neural
Networks with Java - this is an impressively designed site by
Jochen Fröhlich from Germany. (For some reason, most neural network sites tend
to be outside the USA. Wonder why?) He has written a class library that is
available for download from his site, and it includes Java class files for
backpropagation networks and Kohonen networks. Kohonen networks are a form of
self-organizing map that requires no supervision during training. They are
particularly good at solving the "traveling salesman" problem and there is a
beautiful applet at his site that shows one doing just that. This is a site
worth a visit, especially if you're a traveling salesman.
David W. Clark's Neural Networks
Web Site -This David W. Clark guy looks serious- I'm pretty certain
that he appears somewhere in "the literature". His applets are very advanced and
may be somewhat counterintuitive to those not familiar with artificial neural
networks. However, if you are up to the material, give his site a look.